On-Prem RAG Deployment
A Vector Database is a specialized database designed to store, manage, and process collections of vector embeddings—numerical representations of data such as text, images, or audio. Unlike traditional databases, which rely on structured tables and key-value pairs, vector databases operate in a multi-dimensional space, enabling efficient storage, retrieval, and similarity search based on vector distances.
As AI and big data continue to advance, vector databases are becoming essential for handling high-dimensional data. They play a crucial role in machine learning embeddings, recommendation systems, image and video search, natural language processing (NLP), and AI-driven applications. By leveraging vector similarity measures, these databases allow for fast and accurate searches, making them ideal for real-time AI applications.
With the growing complexity of AI models and the increasing volume of data, vector databases provide a scalable and efficient solution for storing, managing, and retrieving vectorized information, driving innovation in AI-powered technologies.
Vector Databases
Vector databases play a pivotal role in various AI and machine learning (ML) applications, including RAG(Retrieval-Augmented Generative)
Retrieval-Augmented Generation (RAG)
Vector databases can be integrated with large language models (LLMs) to build knowledge-based language AI applications. By retrieving relevant information based on vector similarity, they enhance the accuracy of AI-generated responses.
This architecture diagram illustrates RAG's workflow on premises using LLM and vector databases
Architecture Diagram
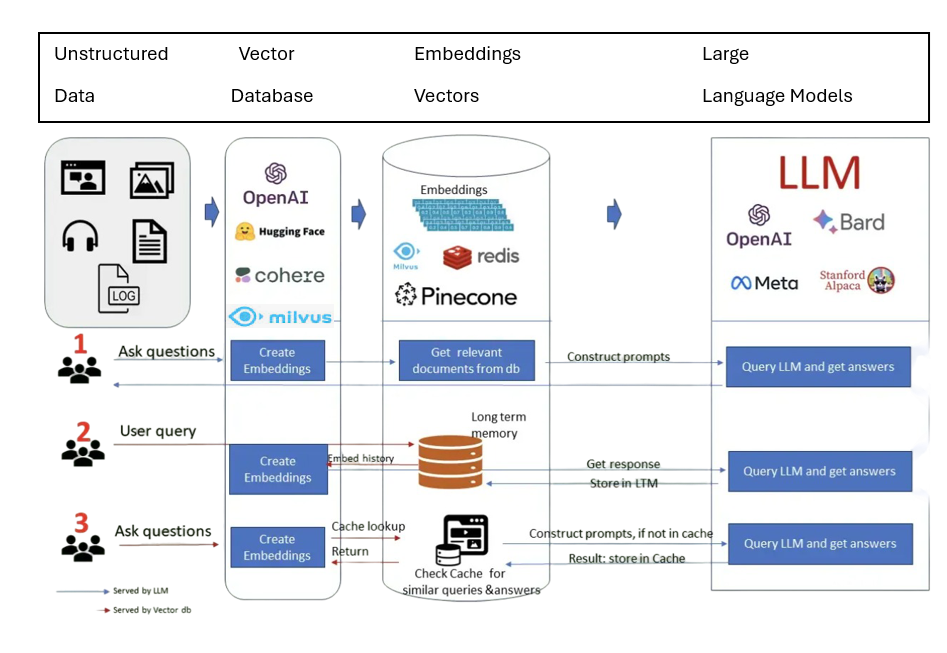
1) Unstructured Documents:The input data consists of various documents to be processed. In this example, the ~120 sample documents are pulled from the S3 bucket.
2) Data Ingestion Pipeline:This is the initial step in which documents are ingested into the system. This pipeline prepares the documents for further processing by extracting relevant information and possibly performing pre-processing tasks like cleaning or formatting the data.
3) Generate Embeddings:After ingestion, the documents are passed to an embedding model. In this case, an opensource Ollama embedding model using LlamaIndex converts the documents into numerical representations (vector embeddings) that capture the semantic meaning of the text.
4) Vector Database:The embeddings generated by the opensource Ollama embedding model using LlamaIndex are stored in a vector database, Milvus, along with the documents. This specialized vector database is designed to handle and efficiently search through large-scale vector data.
5) Query:A user submits a query to the system
6) Query Embeddings:This query is also converted into an embedding to compare it with the document embeddings stored in Milvus.
7) Search Documents:The similarity between query and document embeddings is calculated, with documents ranked higher based on greater similarity.
8) Retrieved Documents:Relevant documents with high similarity are retrieved. The number of documents retrieved, and the similarity threshold can be customized.
9) LLM:The retrieved documents and the query will be sent to the LLM; in our case, the llama3.
10) Result:The response from the LLM is provided to the user.
On-Prem RAG Deployment
The challenges discussed above can be addressed effectively with a common solution: deploying RAG on a private cloud. This approach addresses the issues in the following ways:
1) Better Data Security:Sensitive business documents, regulatory information, and other proprietary data must remain within the secure confines of a private cloud to meet compliance and security standards. If everything is happening privately, there will be no breaches.
2) Lower Cost:Deploying AI models on private cloud infrastructure can offer a more cost-effective solution than public cloud services, especially when frequent usage is required. The cost goes even lower when we use smaller models, as they achieve practical results more efficiently than larger and more resource-intensive models. Due to their rapid innovation and customization capabilities, open-source LLMs and technologies are a great option for your RAG.
3) Enhancing Generation with Retrieval in a Private Cloud:A better retrieval engine can complement a smaller model with limited generative skills. Only by making a better retrieval system can the accuracy and efficiency of AI applications, such as document parsing, text chunking, and semantic querying, be improved significantly.
Key challenges deploying RAG
arge Language models can be inconsistent. Sometimes, they offer precise answers but can also produce irrelevant information. This inconsistency arises because LLMs understand statistical relationships between words without truly grasping their meanings. Additionally, LLMs are pre-trained on outdated and publicly available data, limiting their ability to provide accurate answers specific to your private data or the most recent information. RAG is a popular technique to address this limitation by enhancing the LLM’s responses with external sources of knowledge stored in a vector database like Milvus, thus improving content quality. While RAG is an exceptional technique, deploying it presents challenges.
1) Data Privacy and Security Concerns: Many enterprises, especially those in the finance and legal sectors, hesitate to use public cloud services due to privacy and security concerns. Many existing solutions also focus on public clouds rather than on-premise, which poses challenges for companies needing to ensure data security and compliance.
2) Elevated Costs: Public cloud infrastructure frequently using large-scale models can run up bills. Paying such a hefty bill while lacking full control and ownership of the infrastructure, data, and applications results in a lose-lose situation.
3) Neglecting Retrieval Strategies:One crucial aspect often overlooked is the importance of retrieval strategies in RAG deployment. While AI teams tend to focus on generative AI capabilities, the quality of retrieved documents is equally vital.
Conclusion
As AI adoption continues to grow, interacting with data has become more seamless than ever. However, concerns about data privacy and security still prevent many enterprises from migrating to the cloud. LlamaIndex offers a powerful alternative by enabling organizations to build AI systems on-premises, ensuring greater control, cost efficiency, and data protection. By integrating LlamaIndex with the Milvus vector database, enterprises can harness the power of vector similarity search and large language models (LLMs) to query their private datasets securely. Milvus, a leading open-source vector database, efficiently stores, processes, and searches billion-scale vector data. When a query is made, Milvus retrieves the top-K most relevant results, providing critical context for the LLM to generate accurate and insightful responses. This combination of on-prem AI solutions and vector search technology empowers businesses to leverage AI without compromising data security, making AI-driven insights more accessible and reliable.